What happens when you select count(*) in MySQL
When working with databases, more specifically MySQL, whenever you want to calculate the count of rows, the obvious way to do that is by using the COUNT() function.
You would pass in the column name or * to the COUNT() function and it will return the number of rows in the result set. For instance, if you want to calculate the number of users in the users table, you would do something like this.
SELECT COUNT(*) FROM users;
But do you know what happens behind the scenes when you run this query? I learned about this recently (courtesy of this video by PlanetScale) and I thought it’s worth sharing.
So, contrary to popular belief, the COUNT() function doesn’t count the rows based on what you pass into the function. It doesn’t count the rows based on the column name or * you pass in the function.
Instead, it uses an internal algorithm to find out which row would be the fastest to count. It uses the index to find out the fastest row to count.
To check this, we can use the EXPLAIN keyword in MySQL. It will tell us how MySQL will execute the query. So, if we run the following query with the EXPLAIN keyword, it will look something like this.
EXPLAIN SELECT COUNT(*) FROM users;
And here’s the output.
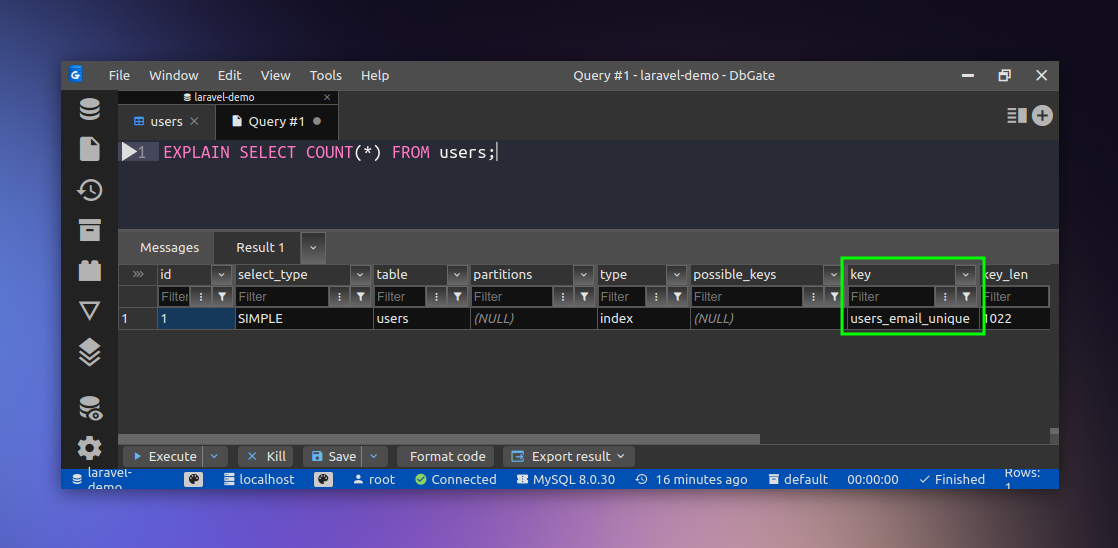
Notice the key column in the output here. It says users_email_unique which is the column that MySQL has inferred to be the fastest to count.
So, even if you pass in the column name, for instance, id in the COUNT() function, it will still use the users_email_unique column to count the rows.
So, next time when you use the COUNT() function, you know what’s happening behind the scenes!

👋 Hi there! This is Amit, again. I write articles about all things web development. If you enjoy my work (the articles, the open-source projects, my general demeanour... anything really), consider leaving a tip & supporting the site. Your support is incredibly appreciated!


